AMD Succeeds in its 25x20 Goal: Renoir Crosses the Line in 2020
by Dr. Ian Cutress on June 25, 2020 9:00 AM EST
One of the stories bubbling away in the background of the industry is the AMD self-imposed ‘25x20’ goal. Starting with performance in 2014, AMD committed to itself, to customers, and to investors that it would achieve an overall 25x improvement in ‘Performance Efficiency’ by 2020, which is a function of raw performance and power consumption. At the time AMD was defining its Kaveri mobile product as the baseline for the challenge – admittedly a very low bar – however each year AMD has updated us on its progress. With this year being 2020, the question on my lips ever since the launch of Zen2 for mobile was if AMD had achieved its goal, and if so, by how much? The answer is yes, and by a lot.
In this article we will recap the 25x20 project, how the metrics are calculated, and what this means for AMD in the long term.
Renoir 2020: New Silicon, Goal Achieved
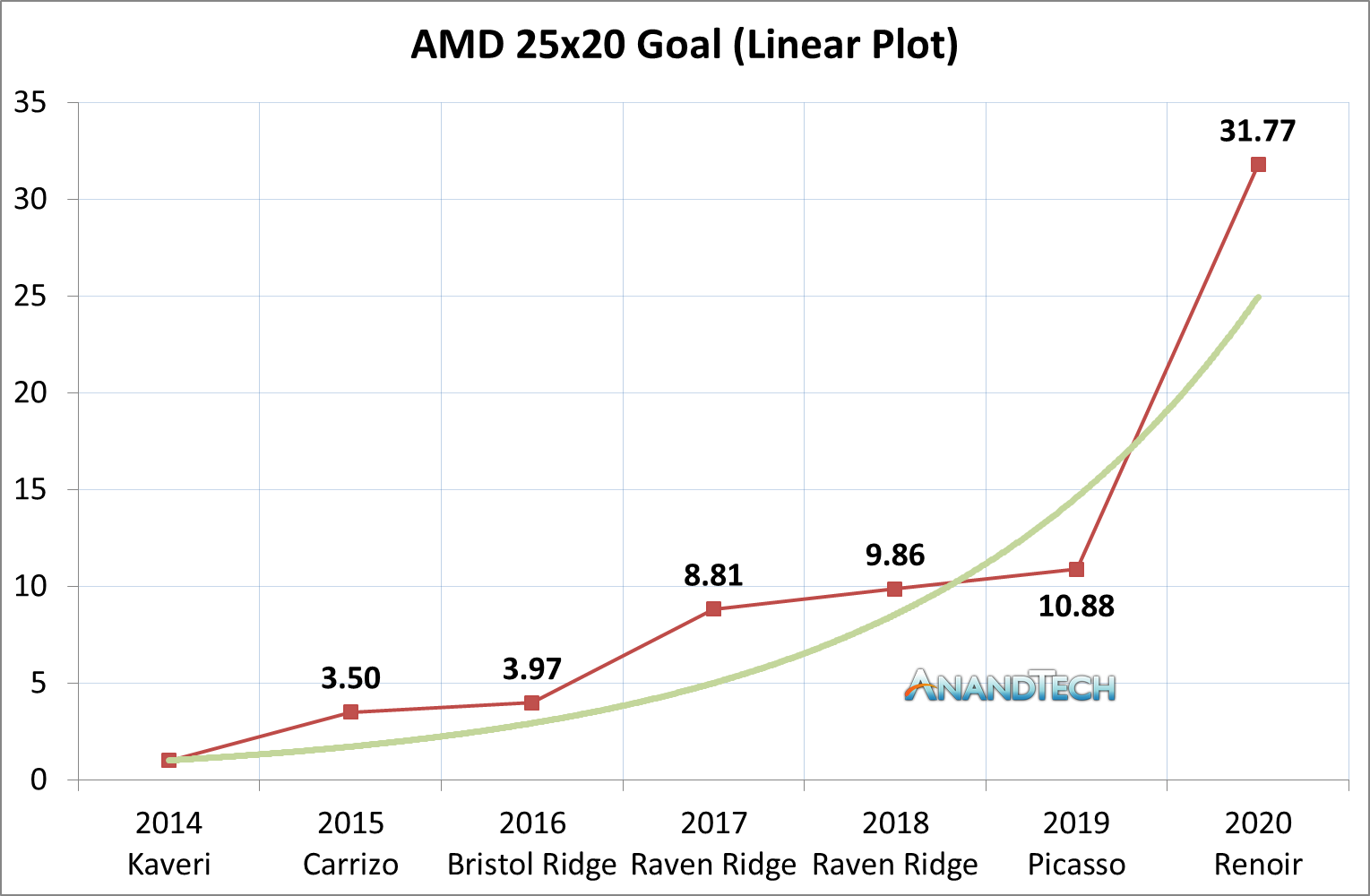
The announcement today from AMD confirms the company has reached its goal of 25x performance efficiency by the end of 2020, starting from the Kaveri baseline. Here’s the important graph:
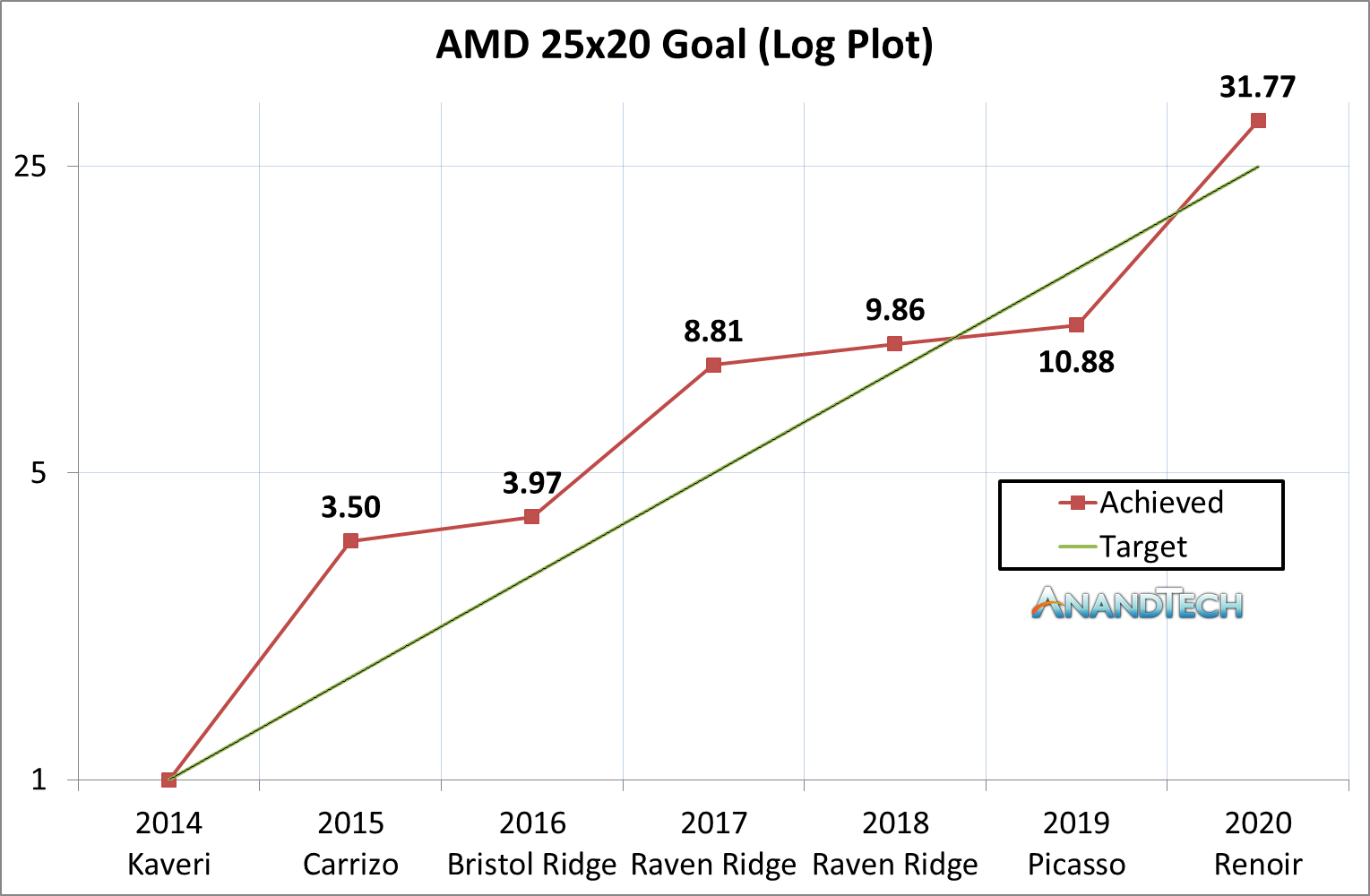
As we can see using this metric, there were big jumps from Kaveri to Carrizo, Bristol Ridge to Raven Ridge, then a series of stagnation over Zen/Zen+, before finally a bump up to Renoir. This gives three distinct jumps:
- Kaveri to Carrizo was 3.5x,
- Bristol to Raven was 2.2x,
- then Picasso to Renoir was 2.92x
The base value for AMD’s goal is on its Kaveri mobile processors, which by the standards of today set a very low bar. As AMD moved to Carrizo, it implemented new power monitoring features on chip that allowed the system to offer a better distribution of power and ran closer to the true voltage needed, not wasting power. After Carrizo came Bristol Ridge, still based on the older cores, but used a new DDR4 controller as well as lower powered processors that were better optimized for efficiency.
A big leap came with Raven Ridge, with AMD combining its new highly efficient Zen x86 cores and Vega integrated graphics. This heralded a vast improvement in performance due to doubling the cores and improving the graphics, all within a similar power window as Bristol Ridge. This boosted up the important 25x20 metric and keeping it well above the ‘linear’ gain.
From 2017-2019, this was ultimately a lull in AMD’s strategy, namely because there were no significant design changes. The versions of 2017/2018 Raven Ridge come down to slight SKU differences used for the metric, but ultimately when it came time to measure the systems AMD was a little out of cycle here. Moving from Raven Ridge to Picasso was a shift from using GlobalFoundries 14nm to 12nm, which affords a slight power gain but not so much on the performance. Going from 2017 to 2019 still yielded a 23.5% gain within the same product family, mainly due to minor manufacturing updates and better binning or power algorithms. It was around the Picasso time when OEM’s started taking AMD’s notebook platform more seriously, especially as the lead up to 2020’s Renoir.
The jump from Picasso to Renoir has been well documented. Our first use of the CPUs, reviewed in the ASUS Zephyrus G14, left us with our mouths open, almost literally. We called it a ‘Mobile Revival’, showcasing AMD’s transition over from Zen+ to Zen2, from GF 12nm to TSMC 7nm, along with a lot of strong design and optimization on the graphics side. The changes from the 2019 to the 2020 chip include doubling the core count, from four to eight, improving the clock-for-clock performance by 15-20%, but also improving the graphics performance and frequencies despite moving down from an silicon design that had 11 compute units down to 8. This comes in line with a number of power updates, adhering to AHCI specifications, and as we discussed with Sam Naffziger, AMD Fellow, supporting the new S0ix low power states has helped tremendously. The reduction in the fabric power, along with additional memory bandwidth, offered large gains.

The jump from Picasso to Renoir is 2.92x, taking AMD to 31.77x over the original target. Goal achieved, and kudos to AMD’s teams that have succeeded at this ambitious target.
How did AMD define how the target will be measured? That’s in the fine print.
Calculating X: Get Me Some X Factor
AMD calls the value it calculates as X, defined as the ratio between a performance metric C and an efficiency metric E. In 2017, it gave detailed notes on how it calculates these values:
- Overall performance efficiency X is C divided by E
- Performance C is a 50:50 average pf CPU and GPU performance compared to Kaveri
- CPU Performance from Cinebench R15 nT Score
- GPU Performance from 3DMark 11 P Score - Energy Use E is defined by ETEC 'Typical Energy Consumption from Notebooks' as per Energy Star Program Requirements, Rev 6.1 Oct-2014
- Kaveri is the baseline where X = 1
The secret sauce is based on how you calculate C and E. The headline equation is as stated above:
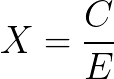
The compute metric C is relatively easy to understand. Here AMD takes the 50-50 weighted average of CPU and GPU performance with the Cinebench R15 multi-threaded test and 3D Mark 11 P full benchmark.

Using Kaveri as a base result of 1.0, Carrizo scores 1.23, Bristol Ridge scores 1.36, and Raven Ridge 2017 scored 2.47 etc.
The efficiency metric E is vastly more complicated. It relies on a ‘typical energy use’ model defined by ETEC Energy Star program that adds weights based on sleep power, idle power, and some loading power. The equation looks a little like this:
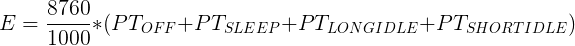
The PT(x) options are the power consumed in those modes. The main thing to bring up about this metric is that it ends up being highly dependent on the device or laptop the processor is being used in. If you want the best result, you need a device that has a low powered, preferably low resolution but efficient display, a small efficient SSD, as few controllers as possible, and as much thermal headroom as possible. The best environment becomes this odd hybrid of premium components but low specifications.
For this metric AMD uses their internal reference platforms, which is often based on one of the first devices to launch with the new product. This is where we initially believe that AMD’s improvements kick in – the first devices in 2017 with Raven Ridge were, not to sugar coat it, rather middle-of-the-road. As reported by our sister website Laptop Mag, the HP Envy x360 with Raven Ridge was a repurposed chassis from HP’s catalogue, rather than something hyper optimized. It is likely that AMD’s reference design mirrors this unit a lot, as AMD and HP work very close together. But clearly room for some improvement.
For those keeping track, again the base line for this value is referred back to Kaveri. Kaveri also sets a low bar here, being a 19W TDP processor to begin with, and Carrizo improved the metric a lot through its much more optimized power monitoring and delivery. The goal here is for a lower value, so while Kaveri scored a value of E of 1.00 as the baseline, Carrizo was 0.35, Bristol Ridge was 0.34, and Raven Ridge was 0.28, and also gave double the performance of Bristol Ridge. When it came time to Renoir 2020, performance was +75% over Picasso 2019, but also offered 40% lower power as measured by this metric, giving that 2.92x overall gain.
For anyone wondering, the equation for the ‘goal’ line approximates to:
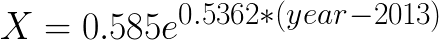
The Final Data
For this disclosure, AMD has given us all the data as collected. We had to have a couple of emails back and forth, because some of the data that AMD provided was different to what it had given us in previous 25x20 disclosures – beyond that, there was some mathematical errors in a number of places. AMD took some time to reconfirm the correct numbers, and admitted that in light of some of the issues I’d found, previous data may have been incorrect as well (at one point they had moved a data point from a 19W CPU to a 35W CPU, among other issues).
With that being said, here are all the platforms that AMD has used for the 25x20 goal:
| AMD 25x20 Systems | |||||||
| CPU | uArch | Base/ Turbo |
GPU CUs |
GPU Freq |
DDR Freq |
TDP | |
| Kaveri 2014 |
FX-7600P | 2 x Steamroller |
2700 3600 |
8 x R7 | 686 | 2 x 4 GB DDR3L-1600 |
35 W |
| Carrizo 2015 |
FX-8800P | 2 x Excavator |
2100 3400 |
8 x R7 | 800 | 2 x 2 GB DDR3-1866 |
35 W |
| Bristol 2016 |
FX-9830P | 2 x Excavator+ |
3000 3700 |
8 x R7 | 900 | 2 x 4 GB DDR4-2133 |
35 W |
| Raven 2017 |
Ryzen 7 2700U |
4 x Zen |
2200 3800 |
Vega10 | 1300 | 2 x 4 GB DDR4-2400 |
15 W |
| Raven 2018 |
Ryzen 7 2800H |
4 x Zen |
3300 3800 |
Vega11 | 1300 | 2 x 8 GB DDR4-3200 |
35 W |
| Picasso 2019 |
Ryzen 7 3750H |
4 x Zen+ |
2300 4000 |
Vega10 | 1400 | 2 x 8 GB DDR4-2400 |
35 W |
| Renoir 2020 |
Ryzen 7 4800H |
8 x Zen2 |
2900 4200 |
Vega8 | 1600 | 2 x 8 GB DDR4-3200 |
35 W |
Note that some of these platforms are not running at their standard TDP designations. This was done for unity across the performance years (which explains some variance in the results over the years), with Raven Ridge 2017 being the sole 15 W data point due to where the product stack was at the time. The Ryzen 7 4800H, used for the Renoir testing, was run in 35W mode (essentially a 4800HS).
And here are the raw results, with the key columns highlighted:
| AMD 25x20 Scores | |||||||
| AnandTech | CB R15 nT |
3DM11 | Compute (C) |
ETEC | Energy (E) |
Performance Efficiency (X) |
|
| Kaveri | 2014 | 232 | 2142 | 1.00 | 0.931 | 1.00 | 1.00x |
| Carrizo | 2015 | 277 | 2709 | 1.23 | 0.327 | 0.35 | 3.50x |
| Bristol | 2016 | 279 | 3234 | 1.36 | 0.318 | 0.34 | 3.97x |
| Raven | 2017 | 667 | 4425 | 2.47 | 0.261 | 0.28 | 8.81x |
| Raven | 2018 | 754 | 4877 | 2.76 | 0.261 | 0.28 | 9.86x |
| Picasso | 2019 | 772 | 5191 | 2.88 | 0.246 | 0.26 | 10.88x |
| Renoir | 2020 | 1727 | 5546 | 5.02 | 0.147 | 0.16 | 31.77x |
Overall AMD has achieved a 5.02x performance gain with a 6.33x idle efficiency, which the company is wrapping up into a combined 31.77x performance efficiency metric.
In speaking with AMD’s Sam Naffziger, he mentioned that when this project started, the company had created what it assumed would be the year-on-year targets for both the CPU and the GPU. Ultimately in 2014 AMD was very big on the heterogenous system architecture, attempting to meld GPU compute in with the CPU. While GPU acceleration has made it into some aspects of a standard laptop-style device, it perhaps isn’t as ubiquitous as was originally envisioned, however the ultimate end-point ended up being a distinct CPU and GPU gain anyway. Sam told me that based on those original targets back in 2014/2015, AMD exceeded his projects in CPU by some considerable margin, which offset some of the GPU projections.
Sam mentioned that one of the key elements to helping achieve this metric was the work AMD has done in idle power management, which has a direct consequence on standard laptop use battery life. Because the 'efficiency' part of the calculation is heavliy weighted towards idle, decreasing the latency for a CPU to enter and exit a turbo mode helps a machine power to idle quicker. Also, optimizing the voltage characteristics of what defines an idle state amd supporting the S0ix power states was also a big leap in that metric. The ACPI standards have helped define some of that roadmap, and some of the requirements imposed by Microsoft in order to enable certain features have driven the design forward.
AMD and x86 vs Arm
As an aside, I did want to get Sam’s thoughts on how AMD is approaching the increasing competition from Arm based designs. Note that we had this briefing well before Apple announced its recent news. Sam stated that Arm designs still have to push both frequency and performance at the high-end, which is going to require some extensive work. He pointed to the tribal knowledge of driving x86 at high-performance and at scale – although he did concede that Arm’s partners have a number of impressive core and SoC designs, and they are keeping tabs on what that market is doing. On top of the core work, Arm’s partners still have the ISA/software porting task, and architecture transitions have to enable significant benefits and lots of investment to be taken advantage of. Sam’s point of view is that AMD has no intention of letting any advantage materialize from the Arm space, and aim to stay several steps ahead at all times. Sam was keen to point out that he believes competition is healthy, and not to dismiss Arm, but to acknowledge that AMD aims to be ahead of the curve if any competition does arise.
‘The Next Five Years Are Going To Be Fun’
At this point I asked Sam if AMD has a similar goal to 25x20 in mind for the next 5-10 years. He was admittedly coy, saying that there is another efficiency goal in the plan, however it would be applied in a much broader context, especially with how the world has changed when it comes to compute requirements. Such a goal would consider a number of performance aspects, perhaps relating to AI acceleration, but also go beyond notebooks into the desktop and the server space – these markets have different performance/energy co-optimization efforts. Sam stated that ultimately AMD plans to focus on what matters most to end-users, what drives to lower energy consumption, and what can offer impressive environmental gains in the future.
I was told that AMD is not going to sit on its laurels any time soon, regardless of where it sits in the competitive landscape. The goal of projects like 25x20 is to create paradigm shifts, either internally or externally, to drive a level of continuous innovation by pushing boundaries. ‘The next five years are going to be fun’, Sam said.
AMD also highlighted its work with TSMC on 7nm, with Sam stating that without it, achieving the goal would not have been possible. Back when the project first started, there wasn’t a clear indication of what TSMC’s 7nm was going to perform like, but by being an early TSMC partner and going deep into design and technology co-optimization, AMD has been able to extract what they need from the process – without that work, Sam predicts that AMD would have barely hit 20x in its performance efficiency goal. Going forward, AMD plan to continue to be lead partners on upcoming process node technologies.
Related Reading
- AMD’s Mobile Revival: Redefining the Notebook Business with the Ryzen 9 4900HS (A Review)
- AMD Updates its 25x20 Goal: Progress in a Generation
- AMD's Progress on Its 25x20 Goal: The Task Ahead
- An Interview with AMD’s CTO Mark Papermaster: ‘There’s More Room At The Top’








82 Comments
View All Comments
neogodless - Thursday, June 25, 2020 - link
I believe Ryzen 4800H is a 45W TDP, although the 4800HS and 4900HS have very similar performance and a 35W TDP.neogodless - Thursday, June 25, 2020 - link
Oops I see the note that it's running at 35W for the tests.ballsystemlord - Thursday, June 25, 2020 - link
Grammar error:"Going forward, AMD plan to continue to be lead partners on upcoming process node technologies."
Missing "s":
"Going forward, AMD plans to continue to be lead partners on upcoming process node technologies."
WaltC - Thursday, June 25, 2020 - link
Actually, if when you say "AMD," you are speaking of a number of people inside AMD, then "AMD plan" is correct, as in, "The people inside AMD plan...", etc.This illustrates why it's doubtful Intel will be catching AMD anytime soon, imo--while Intel was milking its x86 monopoly, AMD was working the chart Ian created for this article. And so it goes. AMD will be a moving target for Intel for the foreseeable future.
mkozakewich - Thursday, June 25, 2020 - link
To expand on that: it's generally an Americanism to think of a company as if they were an individual. You'll notice all British publications will use the plural forms.bji - Thursday, June 25, 2020 - link
It's not about companies being individuals, it's companies being referred to as a singular composite entity. For example we also say "New York plans to introduce a new subway system". Do you in England say "London plan to increase policy presence" or "London plans to increase police presence"? London is a collective of people just like AMD is a collective of people. It makes sense to use the same verb form when referring to such collective entities. Which is why we say "AMD plans ..."ballsystemlord - Thursday, June 25, 2020 - link
@ian is CPU performance measured by the INT or FLOAT unit? I ask because Zen2 did a lot of work on the FPU, but no mention was made on the efforts to improve the INT unit.And thanks for the article, Ian! I've been wondering about this!
mode_13h - Thursday, June 25, 2020 - link
> - CPU Performance from Cinebench R15 nT ScoreThat's going to be mostly FPU performance.
PixyMisa - Thursday, June 25, 2020 - link
Hence the huge leap from the 3750H to 4800H. Twice as many cores and twice the FP width.brucethemoose - Thursday, June 25, 2020 - link
"Such a goal would consider a number of performance aspects, perhaps relating to AI acceleration"Yes please!
But I hope they aren't talking about low-precision zen instructions, as they've been awfully quiet when it comes to RDNA and AI.