Arm Announces The Mali-G78 GPU: Evolution to 24 Cores
by Andrei Frumusanu on May 26, 2020 9:00 AM ESTMore Scaling, Different Frequency Domains
For people unfamiliar with the Mali-G77 and the Valhall GPU architecture, I highly recommend on catching up on last year’s deep dive into the changes of the design, as very much the majority of those key elements are still very much present on the new Mali-G78.
Read: Arm's New Mali-G77 & Valhall GPU Architecture: A Major Leap

From a high top-level perspective, the biggest visible change for the new G78 is the promise that it’ll be able to scale up again to 24 GPU cores. For the last few generations of Mali architectures Arm seemingly has been playing catch-up with trying to consolidate their GPU cores into bigger building blocks, with each successive GPU release always trying to improve the per-core performance rather than just adding in more cores.
Last year when Arm had released the G77 the company did exactly this, as pretty much a G77 core is roughly equal in capability to two G76 cores. Chipsets such as the Exynos 990 and Dimensity 1000 had “reasonable” core numbers of 11 and 9, bringing down the core count compared to past Mali GPUs. There’s still a stark contrast to other mobile GPU microarchitectures, such as Qualcomm’s current 2-core Adreno or Apple’s 4-core designs. The problem with scaling up performance with smaller cores is that this is never as power efficient as scaling up fewer bigger cores, as the latter have less duplication of functions, meaning fewer overhead transistors to burn power.
In a sense, the Mali-G78 here scaling up to 24 cores again seems like a step backwards. I had feared that the company had still gone with too small a core on the G77/Valhall architecture, as now seemingly we’re going to have core-count creep again in order to scale up performance.
Configuration wise, the one thing that Arm did away with is the option of a 4MB L2. While the company says it still retains this capability, no vendor had ever chosen to go with such an implementation, with essentially all Mali GPUs to date using 2MB options.

From an execution core perspective, the Mali-G78 remains identical to last year’s G77. The big changes to past G76 designs and prior was the consolidation of multiple execution engines into a single much wider unit, that had also doubled up on the SIMD and warp width of the execution lanes.
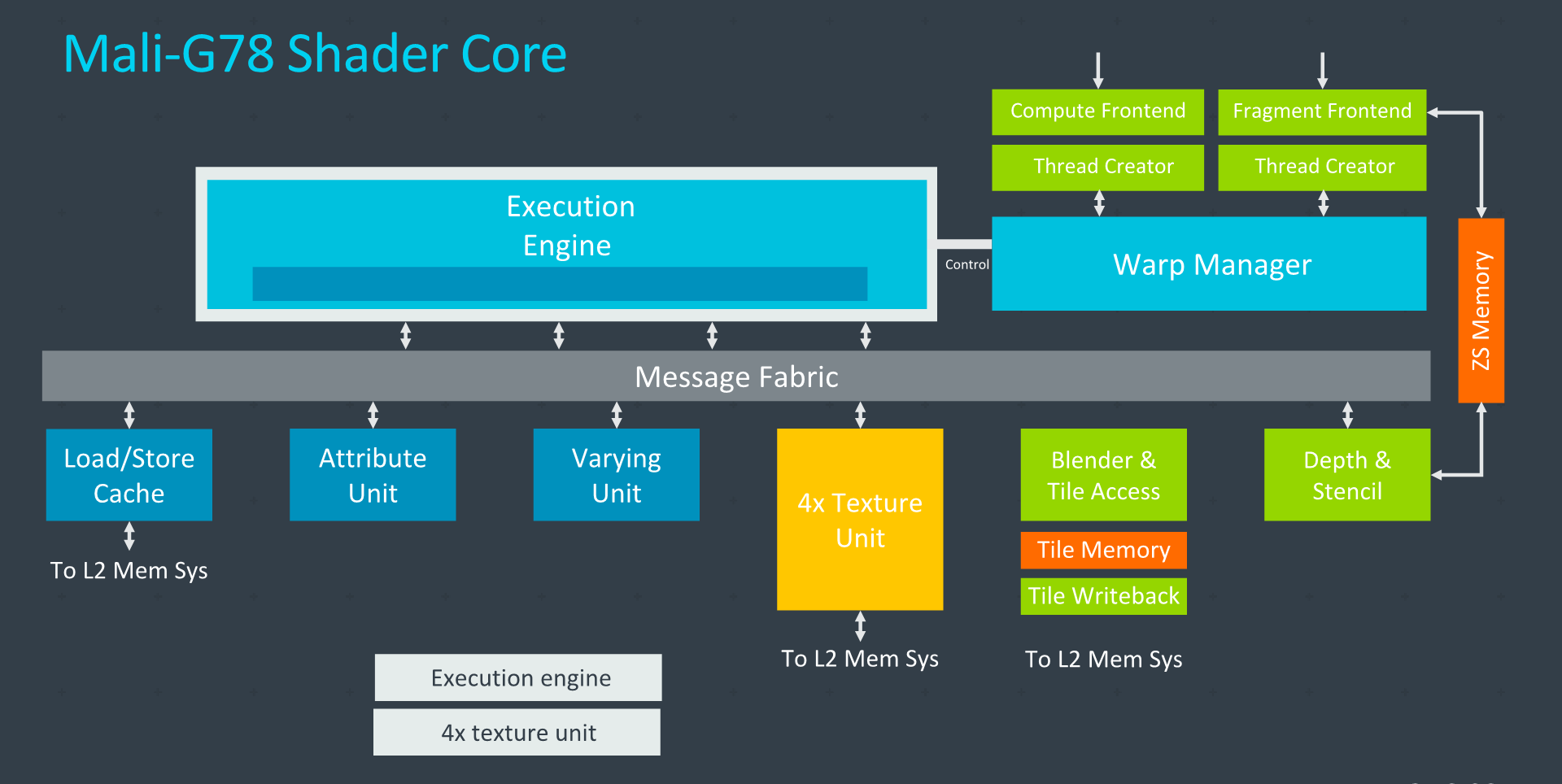
The overall core block diagram also remains the same. Key aspects here is the single execution engine, and a quad-pumped texture unit that supports up to 4 texels per clock filtering capability and 2 pixel per clock render output.
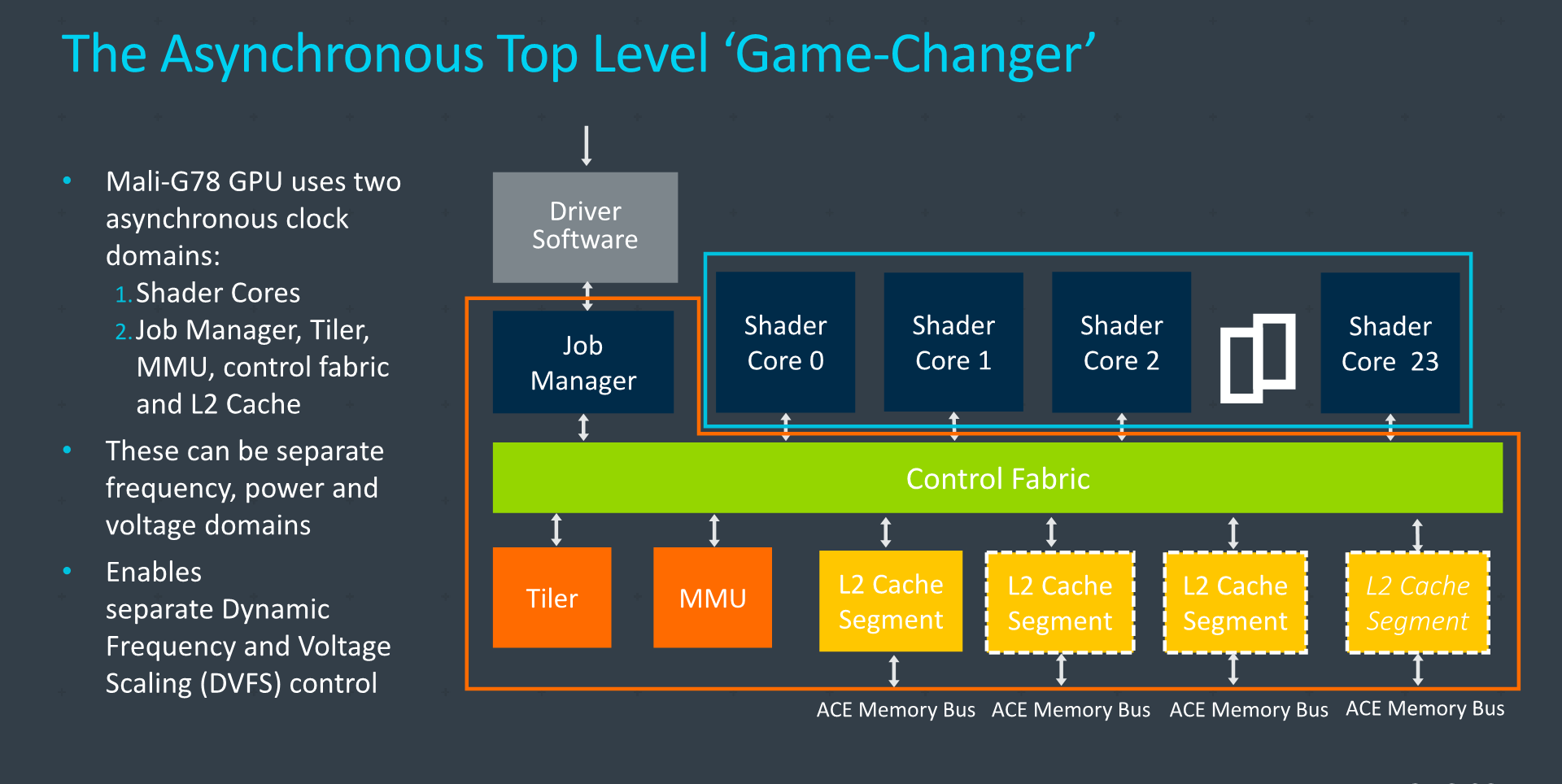
The one key changed of the Mali-G78 that Arm had talked about the most, was the change from a single global frequency domain for the whole GPU to a new two-tier hierarchy, with decoupled frequency domains between the top-level shared GPU blocks, and the actual shader cores.
In essence, Arm is introducing asynchronous clock domains within the GPU, allowing the shader cores to operate at a different frequency to the rest of the GPU. This actually can go both ways, with either the cores going faster, or actually slower, than the memory subsystem and tiler blocks.

The main rationale behind this change is to address two problems: geometry throughput and memory throughput for different workloads. In essence, Arm’s GPU architecture has one big problem, and that is that for the GPU to push out a higher number of polygons on screen, the architecture has no option other than trying to scale up its operating frequency. The tiler and geometry engine here are still only able to process a single triangle per clock, and that metric is fixed and non-scalable across GPU configurations.
In recent years, we’ve seen a change in the mobile GPU landscape, particularly with desktop originating titles such as Fortnite and PUBG making it to our smartphones. One aspect of these newer games is that they’re much more geometry heavy than your usual past mobile titles, and seemingly this has become a problem for the Mali architecture.
Arm’s introduction of different frequency domains is a relatively smart solution to the problem. If you can decouple the frequency between your tiler and geometry engine and the actual GPU cores, you can actually solve the issue of there being an imbalance between geometry throughput that’s not scalable in width, and the core-scalable throughput of compute, texturing and pixel engines.
Furthermore, this decoupling also allows to operate the GPU to operate at different voltages between the two domains. The slower domain would be able to operate at a lower frequency and voltage, thus gaining power efficiency, all whilst in theory not impacting performance. The problem with this is that it now forces the SoC vendor to implement an additional voltage domain and power rail – which can add to the costs of the system.
While this all sounds good, I can’t help but think of this being a band-aid solution to a more fundamental problem of the Valhall GPU architecture. The fact that the architecture is only able to support one tiler and geometry engine is the core limitation that lead to this asynchronous top level to be implemented. In the desktop world, we saw the difficult switch to multi-geometry engine architectures almost a decade ago, and it seems to be that the need of such a redesign is also creeping up to the mobile space.
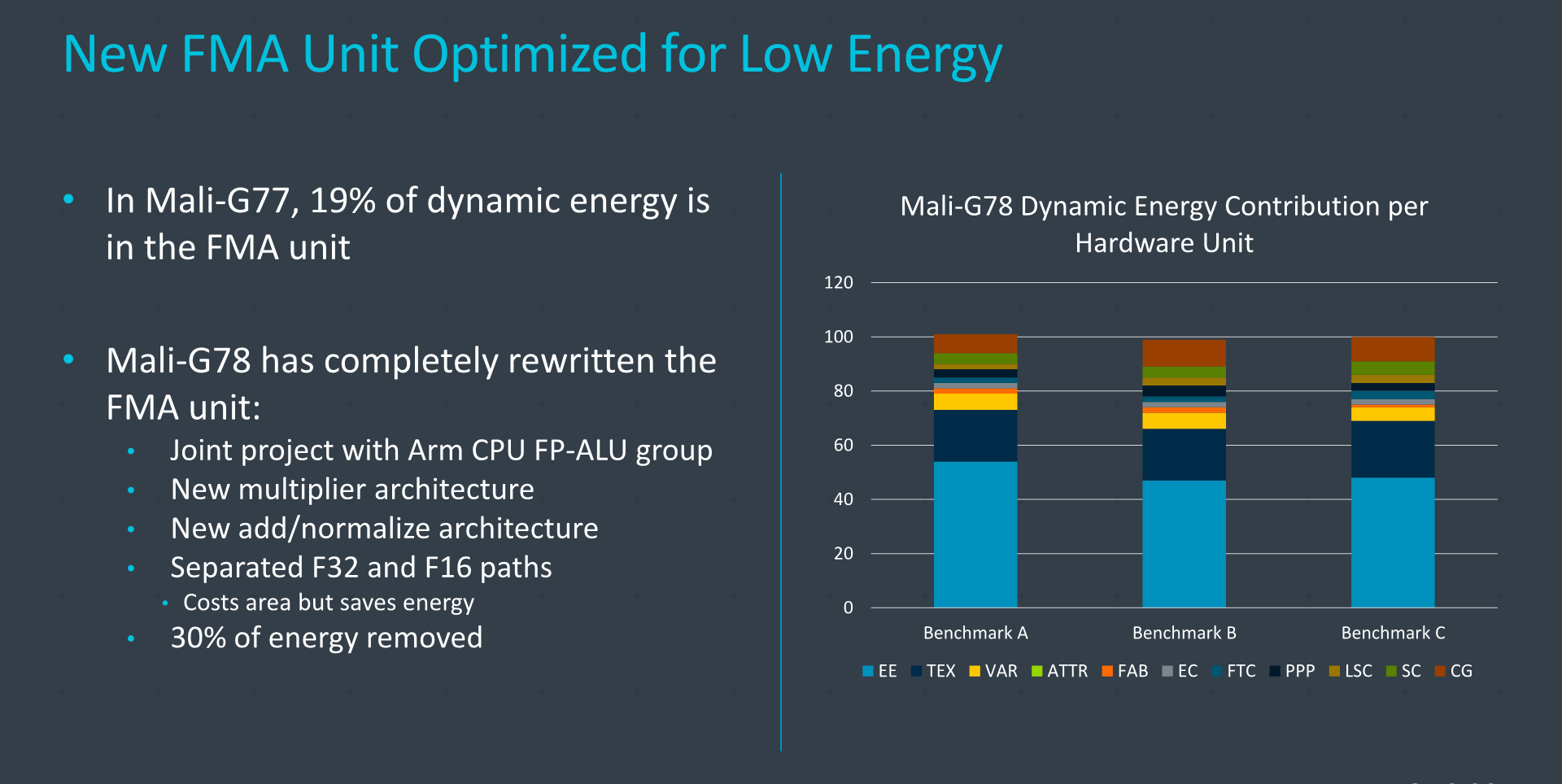
Another significant change the G78 bring is the complete rewrite of its FMA engines. This is said to be a joint-effort with the Arm CPU group, and has resulted in a 30% energy reduction. Key aspects here were the physical separation of the FP32 and FP16 paths, which does cost more transistors and area to implement, but it will have less actual switching transistors when actively operating.
In the G77, Arm says that the FMA units alone accounted for 19% of the dynamic switching energy of the whole GPU. A 30% reduction of that slice means an overall 5-6% improvement of the energy efficiency of the whole GPU, just by that one change.

Finally, a change in the efficiency of the design is improvements in the tiler that allows it to better scale with the increased core counts. The core’s cache shave also had they cache maintenance algorithms improved with better dependency tracking, allowing for the cores to more smartly handle cache data and to avoid unnecessary moving of data which results in a reduction in internal GPU bandwidth as well as power (Or more performance thanks to more available bandwidth).








36 Comments
View All Comments
Iketh - Tuesday, May 26, 2020 - link
reading that was pulling teethhere's your paragraph:
"The async feature from an energy efficiency perspective is proclaimed to be around 6-13% depending on the workload. This is actually a bit of a more complex figure in my view. The main problem in my view is that to achieve this, the SoC vendor needs to actually go ahead and employ a second voltage rail for the GPU to gain the most benefit of the asynchronous frequencies. The efficiency benefit here is small enough, that it begs the question if it’s not just cheaper to add in a few more extra cores and lock them lower, rather than incurring the cost of the extra PMIC rail, inductors and capacitors. It’s an easy efficiency gain for flagship SoCs, but I’m really wondering what vendors will be deploying in the mid-range and lower."
here's the same paragraph cleaned up a bit:
For energy efficiency, the async feature claims to improve 6-13% depending on the workload. This seems difficult to implement in my opinion. The main problem is the SoC vendor needs to employ a second voltage rail for the GPU to see the biggest benefit of asynchronous frequencies. The efficiency benefit is small enough that it begs the question if it’s cheaper to simply add more cores and clock them lower rather than incurring the cost of the extra PMIC rail, inductors, and capacitors. It’s an easy efficiency gain for flagship SoCs, but I wonder what vendors will deploy in the mid and low range.
psyclist80 - Tuesday, May 26, 2020 - link
Thanks Teach, here's your apple! now 'eff off...find someone else to pick on to satisfy your egoCellar Door - Tuesday, May 26, 2020 - link
Actually - it is your reading comprehension, that is the issue here.Please, refrain from blaming others for it.
jjpaq - Tuesday, May 26, 2020 - link
Are you arguing that it's pointless to ever edit text for concision and interest?The extra commas sprinkled throughout your reply seem to make his point perfectly.
Spunjji - Thursday, May 28, 2020 - link
Are you familiar with the concept of a straw man? 🤦♂️dotjaz - Tuesday, May 26, 2020 - link
Nope, I can understand the original article effortlessly but it doesn't mean it's pleasant to read.mkozakewich - Wednesday, May 27, 2020 - link
No, he seemed noticeably more flustered. Must have been a deadline.Alistair - Tuesday, May 26, 2020 - link
Nice. It is nice to see simple and direct language.judithesanchez68 - Thursday, May 28, 2020 - link
Make money online from home extra cash more than $18k to $21k. Start getting paid every month Thousands Dollars online. I have received $26K in this month by just working online from home in my part time.every person easily do this job by just open this link and follow details on this page to get started… WWW.iⅭash68.ⅭOⅯSpunjji - Thursday, May 28, 2020 - link
I agree that the original paragraph could have been cleaned up, but I actually found yours not a lot better.